Get autonomous ai agents 2026 right
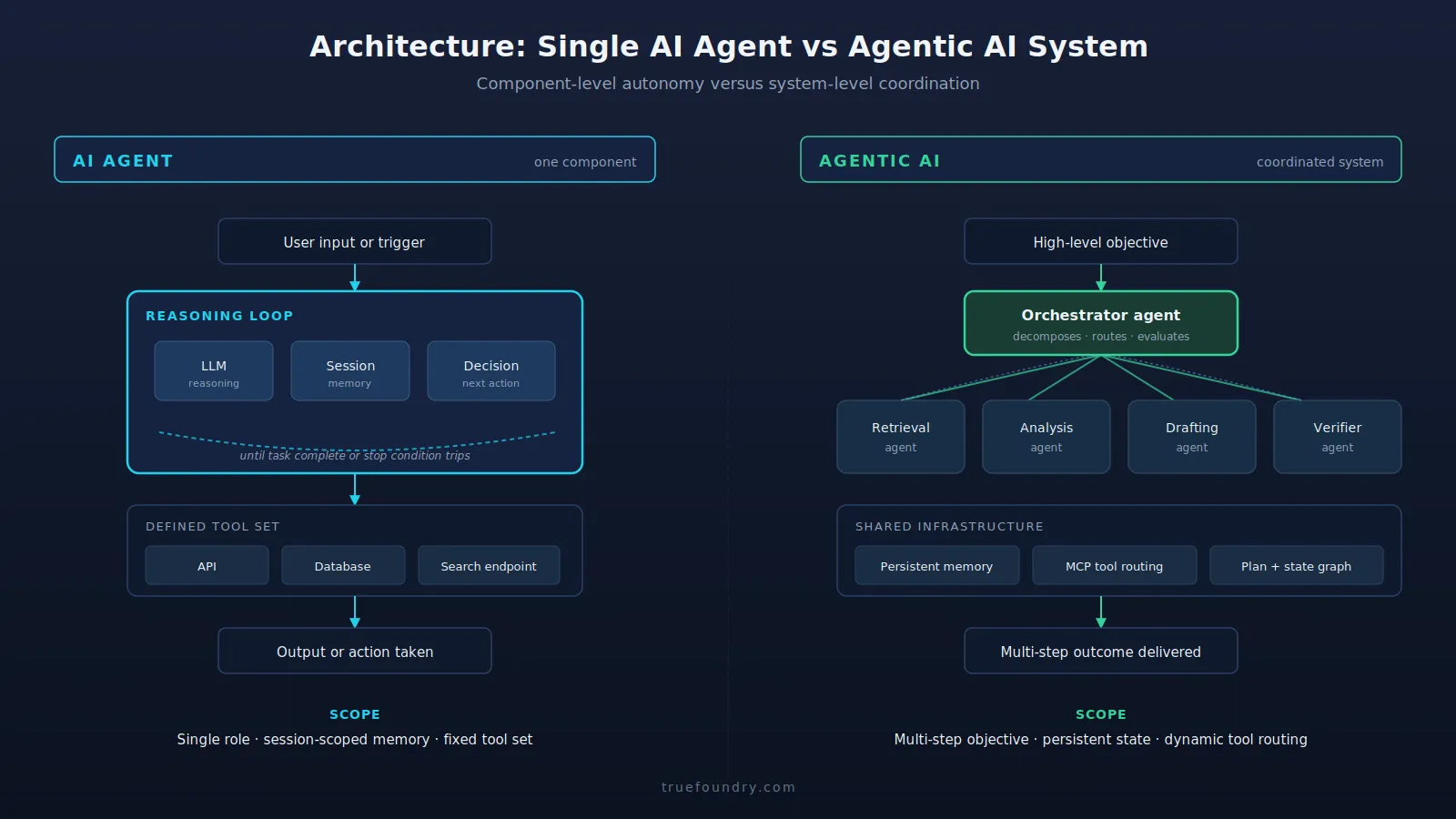
Before deploying multi-agent systems, define the operational boundary. Traditional workflows rely on human oversight for every step; autonomous agents require explicit guardrails to prevent scope creep. Start by mapping the exact handoffs between your primary orchestrator and specialized sub-agents. Ambiguity in these boundaries is the leading cause of infinite loops and resource waste.
Next, audit your data infrastructure. Autonomous agents in 2026 operate best with structured, real-time access to verified sources. If your data lives in siloed legacy databases without clean APIs, the agents will hallucinate or fail to execute. Ensure your environment supports low-latency retrieval, as latency directly impacts the agent's ability to correct its own errors in real time.
Finally, establish a feedback mechanism. Unlike static scripts, these systems learn from interaction. Implement a logging layer that captures not just the output, but the reasoning path. This allows you to trace failures back to specific decision nodes, enabling you to refine prompts or tool definitions without rebuilding the entire system.
Set up the autonomous AI agent workflow
Traditional workflows rely on humans to copy data between tools and trigger the next step. Autonomous AI agents close that loop. They plan, act, and verify without constant supervision. This guide walks through the core steps to build a multi-agent system that replaces manual handoffs.
1. Define the agent’s scope and autonomy level
Start by mapping the specific task. Is it a single lookup or a multi-step process? Define the boundaries. An autonomous agent needs clear rules for when to stop and when to escalate. Avoid giving it blanket access to your entire codebase or database. Instead, scope it to a specific module or data set. This limits the blast radius if the agent makes a mistake.
2. Connect the agent to the necessary tools
Agents don’t work in a vacuum. They need access to APIs, databases, or version control systems. Use a secure gateway to expose only the functions the agent needs. For example, a coding agent might need read/write access to a specific repository and a linter API. Ensure these connections are authenticated and logged. This visibility is critical for debugging later.
Map the specific task and define clear rules for when the agent should stop or escalate. Limit access to a specific module to reduce risk.

Expose only the necessary APIs and databases. Use authenticated connections and enable logging for every action the agent takes.
Add a secondary agent or a static analysis tool to review the work. The primary agent produces output; the verifier checks it against criteria before it goes live.

Run the agent in a sandboxed environment. Use edge cases to see how it handles errors or unexpected inputs before deploying to production.
3. Implement a verification loop
Autonomous agents can hallucinate or make logical errors. A critical step is adding a verification layer. This can be a secondary agent that reviews the first agent’s output, or a set of automated tests. For coding tasks, this means running linting and unit tests automatically. If the verification fails, the agent should be instructed to retry with feedback, not just report the error.
4. Test in a sandboxed environment
Never deploy a new autonomous workflow directly to production. Set up a sandboxed environment that mimics your production stack. Feed the agent realistic but safe data. Watch how it handles edge cases. Does it get stuck in a loop? Does it access the wrong resource? Use these insights to refine your prompts and tool definitions.
-
Scope defined and boundaries set
-
Tool connections authenticated and logged
-
Verification loop implemented
-
Sandbox testing completed and errors resolved
5. Monitor and refine
Once the workflow is live, monitor it closely. Look for patterns in failures. Did the agent struggle with a specific type of code? Did it take too long to complete a task? Use these metrics to refine the prompts and tool definitions. Autonomous agents are not set-and-forget; they require ongoing tuning to stay efficient and accurate.
Common Mistakes in Autonomous AI Agent Workflows
Even with mature multi-agent orchestration, teams frequently undermine their own automation efforts. The shift from chat-based assistance to autonomous execution loops introduces new failure modes that traditional software testing often misses. Below are the most prevalent errors and how to correct them.
Ignoring Agent-to-Agent Communication Protocols
Autonomous agents rarely work in isolation; they pass context, code snippets, and state changes between one another. When these handoffs lack strict schema validation, agents begin to hallucinate missing fields or misinterpret prior instructions. This leads to cascading errors where one agent’s output becomes another agent’s broken input.
Fix this by enforcing rigid JSON schemas for all inter-agent communication. Use a shared context store that validates payloads before processing. Treat agent-to-agent messages like API calls: expect failures, log them, and retry with corrected parameters.
Over-Autonomizing Without Guardrails
Giving an agent full write access to production databases or deployment pipelines is a common but dangerous mistake. Without explicit boundaries, an agent might optimize for speed over safety, deleting critical files or deploying untested code. This is particularly risky in multi-agent systems where one agent’s aggressive optimization can trigger unintended side effects in another agent’s domain.
Implement a "human-in-the-loop" checkpoint for high-risk actions. Use a policy engine that defines what agents can do autonomously versus what requires approval. Start with read-only access and gradually expand permissions as the agent demonstrates consistent reliability.
Neglecting Context Window Management
As conversations grow, agents consume more tokens, leading to slower response times and degraded reasoning quality. Many teams fail to truncate or summarize historical context, causing the agent to lose focus on the current task. In multi-agent setups, this problem compounds as each agent maintains its own conversation history.
Implement automatic context summarization. After a certain number of turns or token threshold, summarize the conversation into a concise state object and discard the raw history. This keeps the agent’s attention sharp and reduces latency.
Failing to Test for Non-Deterministic Behavior
Unlike traditional code, AI agents are non-deterministic. The same input can produce different outputs based on subtle variations in model sampling. Testing only happy paths is insufficient; you must stress-test for edge cases and variability.
Run regression tests with multiple seeds and temperature settings. If an agent’s behavior changes significantly under minor perturbations, it’s not ready for production. Use a feedback loop to continuously refine prompts and system instructions based on observed failures.
Autonomous ai agents 2026: what to check next
Before handing over critical workflows to multi-agent systems, it helps to address the practical friction points teams encounter. The shift from chat-based assistance to autonomous execution loops requires clear boundaries on control, security, and cost.
These questions highlight that autonomy is a spectrum. The goal is not full replacement, but augmented efficiency with reliable safety nets.
No comments yet. Be the first to share your thoughts!