Define the scope for autonomous agents
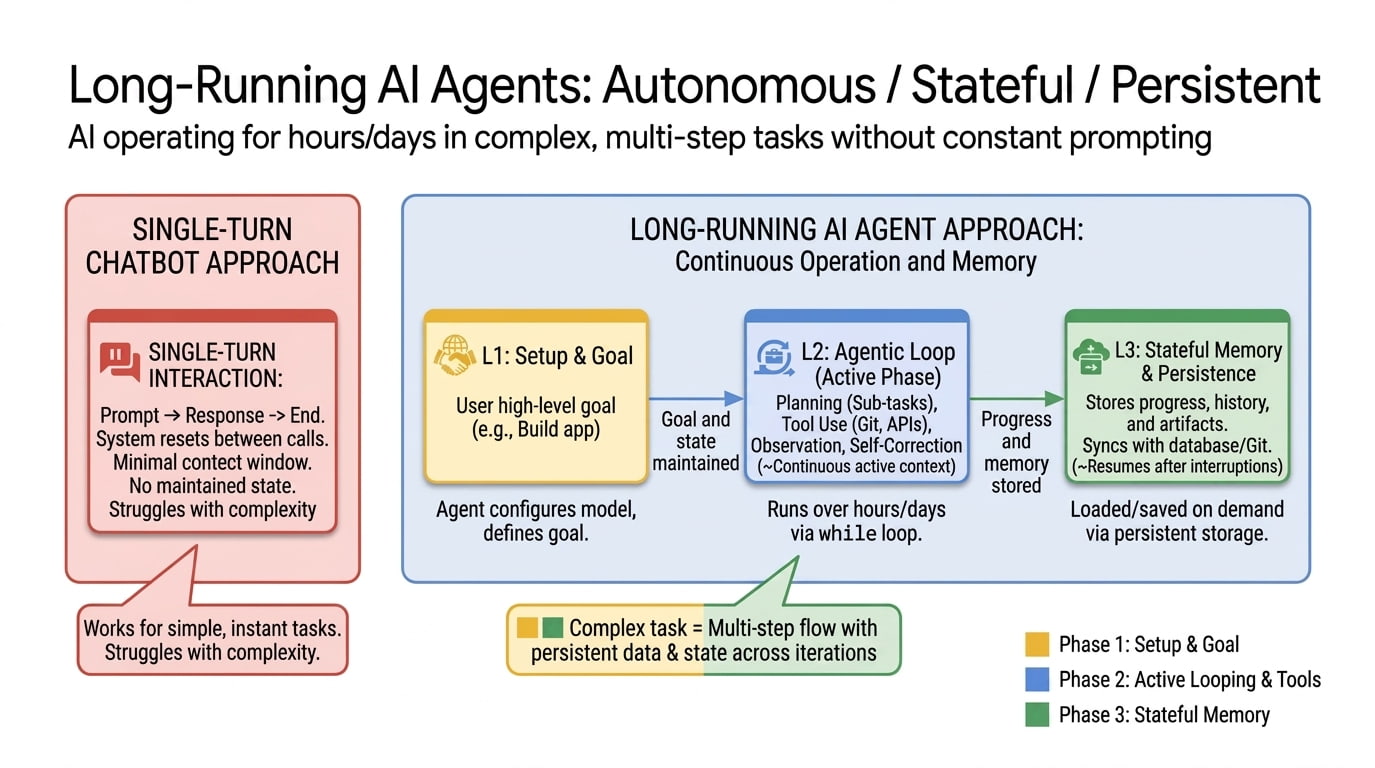
Before writing a single line of code or selecting a model, you must determine where your autonomous agent fits within your current technology stack. The distinction between a traditional SaaS application and an autonomous agent is not just about speed; it is about agency. Traditional software waits for a user to click a button. An autonomous agent perceives its environment, makes decisions, and executes actions with minimal human intervention.
Gartner projects that by 2026, 40% of enterprise applications will include autonomous agents, a significant jump from less than 5% today [src-serp-1]. This shift signals a move from tools that assist users to systems that perform work on behalf of the organization. To avoid over-engineering, start by identifying high-volume, rule-based tasks that currently bottleneck your team.
When defining the scope, ask whether the task requires complex judgment or simply repetitive execution. Autonomous agents excel at the latter. If your workflow involves navigating multiple interfaces, checking data against a set of rules, and triggering an outcome, it is a strong candidate for automation. Avoid starting with ambiguous, creative, or highly subjective tasks where the "correct" answer is open to interpretation.
Your first agent should have a clear beginning, a defined end state, and a measurable outcome. For example, instead of "improve customer service," scope the task as "automatically categorize incoming support tickets and route them to the correct department based on keywords." This precision allows you to measure success and iterate safely. Once you have defined this boundary, you can proceed to selecting the right tools and architectures for deployment.
Select the right model and harness
Choosing an autonomous AI agent requires matching the underlying large language model (LLM) with an orchestration framework capable of sustained, multi-step execution. As of 2026, production-grade autonomy is no longer theoretical; agents can now maintain focus for hours, provided you select the correct tool for the task [src-serp-4]. The decision hinges on three factors: autonomy level, tool access, and cost.
Autonomous agents fall into two primary categories. The first uses specialized agents like OpenAI Operator, which navigates web interfaces directly. The second relies on general-purpose models equipped with computer-use capabilities, such as Anthropic’s Computer Use, which interact with graphical user interfaces through vision and control systems.
Compare these options side-by-side to determine the best fit for your deployment:
| Model | Autonomy Level | Tool Access | Cost Model |
|---|---|---|---|
| OpenAI Operator | High (Web-specific) | Direct browser navigation | ChatGPT Pro Subscription |
| Anthropic Computer Use | Medium (GUI-based) | Screen interaction & clicks | API Pay-per-token |
| OpenAI GPT-4o | Low (Code/Text) | Function calling & APIs | API Pay-per-token |
| Claude 3.5 Sonnet | Medium (Code/Text) | Function calling & APIs | API Pay-per-token |
For web-specific tasks, OpenAI Operator offers the highest autonomy by browsing the web directly [src-serp-5]. However, it is limited to the browser environment and requires a ChatGPT Pro subscription. For broader applications involving desktop software or custom GUIs, Anthropic’s Computer Use provides a more flexible, albeit lower-autonomy, alternative that interacts with any screen element.
If your workflow relies on backend APIs, code execution, or data processing, general-purpose models like GPT-4o or Claude 3.5 Sonnet remain the most cost-effective choice. They do not "see" screens but execute code and call APIs with high precision, making them ideal for structured, non-visual tasks.
Configure tool access and permissions
Autonomous agents cannot operate in a vacuum; they require defined pathways to interact with external systems. Granting the right API access and sandbox environments is the critical step that separates functional automation from operational risk. Without precise permission scoping, an agent might execute valid code but trigger unintended side effects in production databases or third-party services.
The goal is to establish a "least privilege" architecture. Agents should only possess the specific credentials and scopes necessary for their assigned workflow. This approach minimizes the blast radius if an agent encounters an error or behaves unexpectedly. By isolating these permissions, you ensure that the agent handles workflow execution within defined boundaries without requiring constant human oversight for every single step.
Follow this sequence to configure your agent’s environment safely:
Before writing any code, map out exactly which external services the agent needs to touch. List the specific API endpoints, database tables, or SaaS platforms required to complete the task. This inventory prevents scope creep and helps you avoid granting broad, unnecessary access rights during the initial setup phase.

Never use personal or shared administrative credentials. Generate unique service accounts for each agent or agent cluster. These accounts should have their own authentication keys and audit trails. This separation ensures that you can revoke access or rotate keys for one agent without disrupting others or compromising shared infrastructure.
Apply the principle of least privilege by assigning only the minimal permissions required. If an agent only needs to read data, do not grant write or delete access. Use role-based access control (RBAC) to group these permissions. This step is essential for maintaining security posture, especially when dealing with sensitive enterprise software delivery pipelines.
Before connecting to production, deploy the agent in a sandbox that mirrors your live environment but uses dummy data or read-only copies of databases. Run full workflow simulations to verify that the agent respects its permission boundaries. This testing phase catches permission errors and logic flaws before they can impact real users or critical business operations.
Once the sandbox tests confirm stable behavior, you can gradually expand access to production environments. Monitor the agent’s API calls closely during the first few days to ensure it adheres to the defined scopes. Regular audits of these permissions help maintain security as the agent’s responsibilities evolve or as new tools are added to your stack.
Implement guardrails and monitoring
Autonomous agents operate at machine speed, which means a single logic error can cascade into significant operational damage before a human notices. To prevent agent drift, hallucination, or unauthorized actions, you must build a safety layer that functions as a circuit breaker. This section outlines the technical and procedural controls required to keep your agents within defined operational boundaries.
Define strict operational boundaries
Before an agent executes its first task, you must define explicit constraints on what it can access and modify. Use role-based access control (RBAC) to limit permissions to the minimum necessary for the task. For example, a customer support agent should read customer data but never have write access to the billing database.
Implement output validation filters to catch hallucinations before they leave your system. These filters check generated responses against a whitelist of approved facts or formats. If an agent attempts to access a restricted API endpoint or generates a response containing sensitive data patterns (like PII), the system should automatically block the action and log the incident.
Establish real-time monitoring
You cannot secure what you cannot see. Deploy continuous monitoring to track agent behavior, latency, and token usage. Set up alerts for anomalous patterns, such as a sudden spike in API calls or repeated failed authentication attempts, which may indicate a security breach or a misconfigured prompt.
Use logging to maintain a full audit trail of every decision the agent makes. This includes the input prompt, the reasoning steps taken (if visible), and the final action executed. This data is essential for debugging and for meeting regulatory compliance requirements, especially in industries like finance or healthcare.
Conduct periodic safety audits
Guardrails are not "set and forget" components. As your agent interacts with more data and complex workflows, new edge cases will emerge. Schedule quarterly safety audits to review logs, test edge cases, and update constraints.
Involve subject matter experts from legal, compliance, and security teams in these reviews. They can identify risks that engineering teams might overlook, such as subtle bias in decision-making or potential violations of data privacy laws. Treat these audits as a continuous improvement cycle, not a one-time checklist.
Validate performance with real workflows
Before handing control to an autonomous agent, you must prove it can handle the messy reality of production data. Theoretical accuracy on a clean dataset does not guarantee operational stability. You need to stress-test the agent against edge cases, measure latency under load, and verify that it adheres to safety constraints when things go wrong.
Start by running a suite of regression tests that include your most common failure modes. Does the agent hallucinate when given ambiguous instructions? Does it freeze when an external API times out? Log these errors and ensure your error-handling routines trigger the correct fallback actions. If the agent is integrated into a regulated industry, document every decision path for audit trails.
Next, establish clear success metrics. Define what "done" looks like for each task. Is it a 95% accuracy threshold? A specific cost-per-inference limit? Or a maximum response time of two seconds? Set up monitoring dashboards to track these metrics in real-time during the beta phase. If the agent exceeds cost caps or latency limits, it should automatically pause and alert a human operator.
Finally, verify your rollback plan. If the agent starts making incorrect decisions at scale, how quickly can you revert to the previous state or shut it down completely? Test this kill switch. A robust validation process isn't just about proving the agent works; it's about proving you can control it when it doesn't.
-
Test against edge cases and ambiguous inputs
-
Verify error handling and fallback routines
-
Set measurable success metrics (accuracy, latency, cost)
-
Monitor real-time performance in a staging environment
-
Test rollback and kill-switch procedures
Common deployment mistakes to avoid
Even with a solid architecture, autonomous AI agents can fail if deployment practices are overlooked. The most frequent error is over-permissioning. Granting agents broad access to databases or APIs increases the risk of unintended actions or data leaks. Follow the principle of least privilege: assign only the minimum permissions required for the agent to complete its specific task.
Another critical pitfall is neglecting observability. Without detailed logging and monitoring, it is difficult to debug why an agent failed or to trace its decision-making process. Implement structured logging from the start. This ensures that every action, input, and output is recorded, making it easier to audit performance and identify bottlenecks.
Finally, avoid deploying agents without a clear failure recovery plan. Autonomous systems can encounter unexpected errors or edge cases. Define explicit fallback behaviors, such as halting operations or escalating to a human operator, to prevent cascading failures. Testing these recovery paths in a staging environment is essential before moving to production.
Frequently asked questions about agents
How do autonomous agents differ from chatbots?
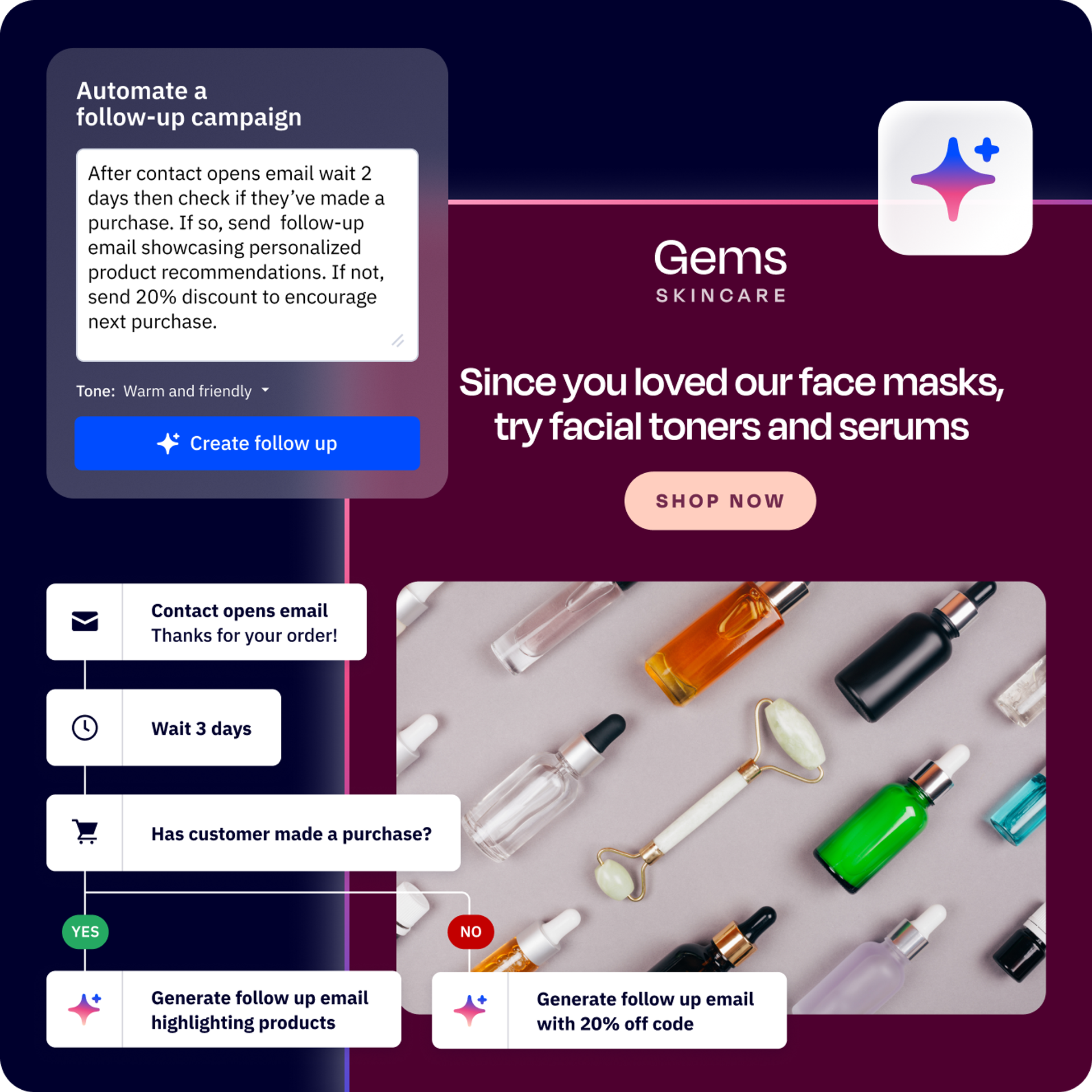
Autonomous agents no longer wait for prompts to act. They monitor triggers and execute tasks end-to-end, closing what experts call the "action gap." This shift marks the transition from passive chatbots to systems that operate independently, a milestone that defines the 2026 AI landscape.
Is data secure when agents access internal APIs?
Security depends on strict identity governance. Agents should use scoped service accounts rather than shared credentials, limiting access to only the specific APIs and data sets required for the task. This principle of least privilege prevents lateral movement if an agent is compromised.
What is the action gap?
The action gap was the technical barrier preventing AI from moving beyond text generation to executing complex, multi-step workflows. Its closure in 2026 enables agents to handle full operational cycles, from diagnosis to deployment, without human hand-holding.
No comments yet. Be the first to share your thoughts!